Open University Learning Analytics
Motivation
Did your educational experience meet every one of your needs exactly? Were you not even slightly over or under challenged in any of your courses? If so, you probably never interacted with online learning systems. If on the other hand, you are familiar with names like Salman Khan, then like me, you engaged with lots of supplemental materials online to succeed academically. Even before COVID-19, online learning platforms had grown in popularity ever since their creation. As is the custom in the data science world, digital platform engagement in masse begs data analysis and optimization. Educators and researchers alike have a vested interest in understanding how students move through learning platforms. Any human being presented with new information engages in the learning process, so theories about learning are more important than ever in the age of digitization. My initial research questions were the following:
- How do students engage in online learning platforms? Can various machine learning models classify or rank student performance accurately?
- If so, which models are suitable for student learning data are the most successful?
- Most importantly, how can the information from this analysis benefit educators, administrators, and online learning platform designers help students succeed, particularly students in danger of failing?
Data
I used data from the Open University Learning Analytics (OULAD) which contains information on student demographics, assessment scores, interaction with the online course modules, and more. This data includes online courses that students take for credit towards a degree. Note that students may have different incentives than in a traditional massive open online course (MOOC) which are usually taken for personal learning of a specific skill.
Analysis
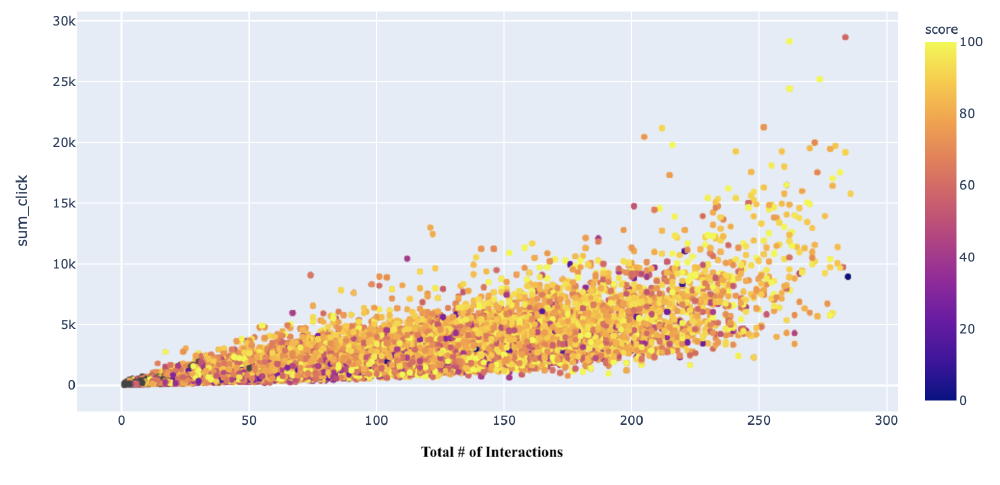
I thought that the total number of clicks and interactions (measured by “sessions” a student was logged in) would give a much clearer gradient, with low scores (darker colored points, above) in the bottom left and high scores (lighter colored points) in the top right. However, the top-most right-most point earned a score of 57, missing a passing grade by only 3 points. How tragic! Further, one of the maximal data points for total number of interactions achieved a score of under 20, which indicates that for this student, repeated interactions were unsuccessful in improving their score.
I did find that increased interactions did, on average, safeguard students against poor scores. Every 50-100 interactions, or ~3000 clicks were able to protect a student by about 10 points out of 100. One confounding factor that is important is to know where this course landed in the prerequisite chain for a student’s overall education. Students who did not need to engage in the online learning platform to succeed will give poor signals for our model, and student who engaged in a halfhearted or distracted manner similarly give equally unhelpful signals.
I carried out a comparative analysis of different models in predicting student outcomes including logistic regression, logit net, ridge classifier, naive Bayes’s, decision trees, random forests, and support vector machines. My goal was to gain insight on the relation between students’ demographics, interaction with online course modules, and their performance in order to enhance student learning in online learning systems. I compared several methods of prediction and made modifications to those methods in order to accurately predict whether students will pass or fail the course. I found that random forest was most effective to classify the student outcomes, but it was not effective in classifying students on the margin (score between 55 and 65), who were of great interest to me, because with a small nudge, I hypothesize they would be able to pass (score > 60). In the future, I would like to explore natural experiments where students had different treatments across the course of learning.
Conclusion
Ultimately, I’m hopeful that educators and researchers will be able to apply the best techniques to their own students and educational data in order to assist in the learning process. With an appropriately partitioned set, perhaps partway through a course a teacher or online learning system would be able to offer encouragement or incentives to keep a student from failing or withdrawing. As the nature of education and the notions of “classroom”, “teacher”, and “course” continue to change, I hope the results will contribute to meaningful analysis to help students succeed.